Has Intel
documented this flaw?
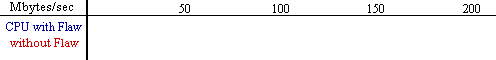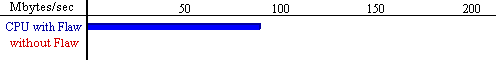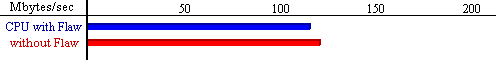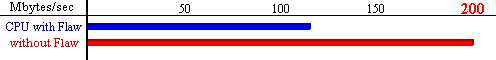
Recently an Intel spokesman claimed that this performance flaw has
been documented 'years ago', and that it can be found on page 43 (3.5.3)
of Intel's
Architecture Optimizations Manual.
On this page, Intel talks about the line fill (=burst) order of its
processors. The only somewhat relevant thing there is the middle paragraph
which states that on a burst the requested word (8 bytes) will be the first
returned and afterwards the other 3 words will follow. Which is exactly
what we said Intel has in its data
sheets.
BUT in the same paragraph it is stated also that "it is preferable
to access memory in sequential order". Exactly that
generates the flaw: when accessing memory or secondary cache sequentially,
the processor's read buffer imposes a penalty
resulting in the bus being under-utilized. We strongly disagree: we access
memory in a special non-sequential
order which results in up to a 71% increase of main memory bandwidth!
But what Intel does not reveal in this page or anywhere else, is that
if one makes afterwards (while the burst has not finished) a request of
another word in the same burst line, then the execution unit waits for
the entire burst to finish (documented) and then there is a considerable
time penalty (the undocumented flaw).
But if while the burst has not finished another read request is made in
a different burst line, there is no penalty; immediately after the current
burst, a new one is generated. Consequently, in order to get rid of
this penalty the workaround is to rearrange the order of read requests,
that is to make them in a special order, non-sequentially.
For most people, this performance flaw/issue/'design decision'/imperfection/etc
is more important than all these Pentium bugs that were found in the past
3 years. For instance, the worst bug, the FDIV bug, occurred only on 1
in 9 billion double precision divisions and then only returned a slightly
wrong result. Intel correctly stated that this bug affected only a small
minority (at most 1-2%) of its customers. But this performance issue
affects everybody all the time, because everybody would have a faster
processor if the read buffer didn't have this penalty, or if programmers,
compiler makers, etc. were aware of that.
We wish to state that we have nothing against Intel, we always admired
Intel's new processors, and we use mostly Intel processors. We just wish
to show programmers how they can make their programs much faster by working
around an undisclosed flaw (or worst a 'design decision') which exists
in all manufacturer's processors. But we generally believe
that there should be no secrecy; what Intel, as the market leader,
decides to put in its new processors everybody who is expected to buy/use/program
them should be allowed to know.
Click here for Schematic
demonstration of the read buffer flaw
If you can
handle it, proceed to in depth technical analysis.
Return to first
page.
For questions, go to the Q&A
page.
For comments or suggestions, mail
us
Intel and Pentium are registered
trademarks of Intel corporation.
All other trademarks are those
of their respective owners.
Everything at this web site is the
property of Intelligent Firmware Ltd. You may not repost/publish this information
without our explicit permission.